MAUDE Signal Explorer
Mining FDA post-market data for use-error signals
Executive Summary
Premise
HFE teams underuse post-market data. MAUDE holds real use errors in reporters' own words—free formative-study input.
Constraints
Public data only; no denominators; keyword heuristics honestly framed as heuristics, not classifiers.
My Role
Solo: method design, data analysis, visual design, and engineering (Next.js + openFDA API).
Outcome
A live, self-updating tool demonstrating a repeatable signal → hypothesis → study-design method.
The premise
Human factors work in medical devices is overwhelmingly forward-looking: formative studies, validation, design controls. The discipline's richest free dataset points the other way. The FDA's MAUDE database holds millions of adverse-event reports—real use errors, in real clinical environments, described in the reporters' own words. Most HFE teams touch it only when a regulator or a complaint forces them to.
I wanted to demonstrate, publicly and on public data, what a human factors engineer can extract from MAUDE with a deliberately simple method—and where the honest limits of that method are.
Why surgical staplers
Surgical staplers are the perfect teaching case. In 2019, investigative reporting revealed that manufacturers had routed tens of thousands of stapler malfunction reports through FDA's “Alternative Summary Reporting” program—invisible to anyone searching public MAUDE. When FDA ended the program, the hidden reports flooded into the public record, and the reporting curve exploded.
That spike is the first lesson the tool teaches: a reporting curve reflects policy as much as risk. Anyone who reads post-market data without knowing its provenance will draw confident, wrong conclusions.
The method
The tool reads ~190,000 stapler reports (product codes GAG and GDW) live from the openFDA device-event API and applies three moves:
- Signal: yearly trends split by event type (malfunction / injury / death), annotated with the ASR policy change so the spike reads as history, not hazard.
- Hypothesis: a use-error phrase lens—counts for phrases like “failed to fire,” “wrong size,” and “inadvertently” that tend to mark perception, cognition, or action failures. Each recurring pattern is a candidate use error for task analysis and PCA classification.
- Study design: the newest narratives, rendered with use-error phrases highlighted, because counts only point you somewhere—the words tell you why. This is where formative scenarios and IFU probes come from.
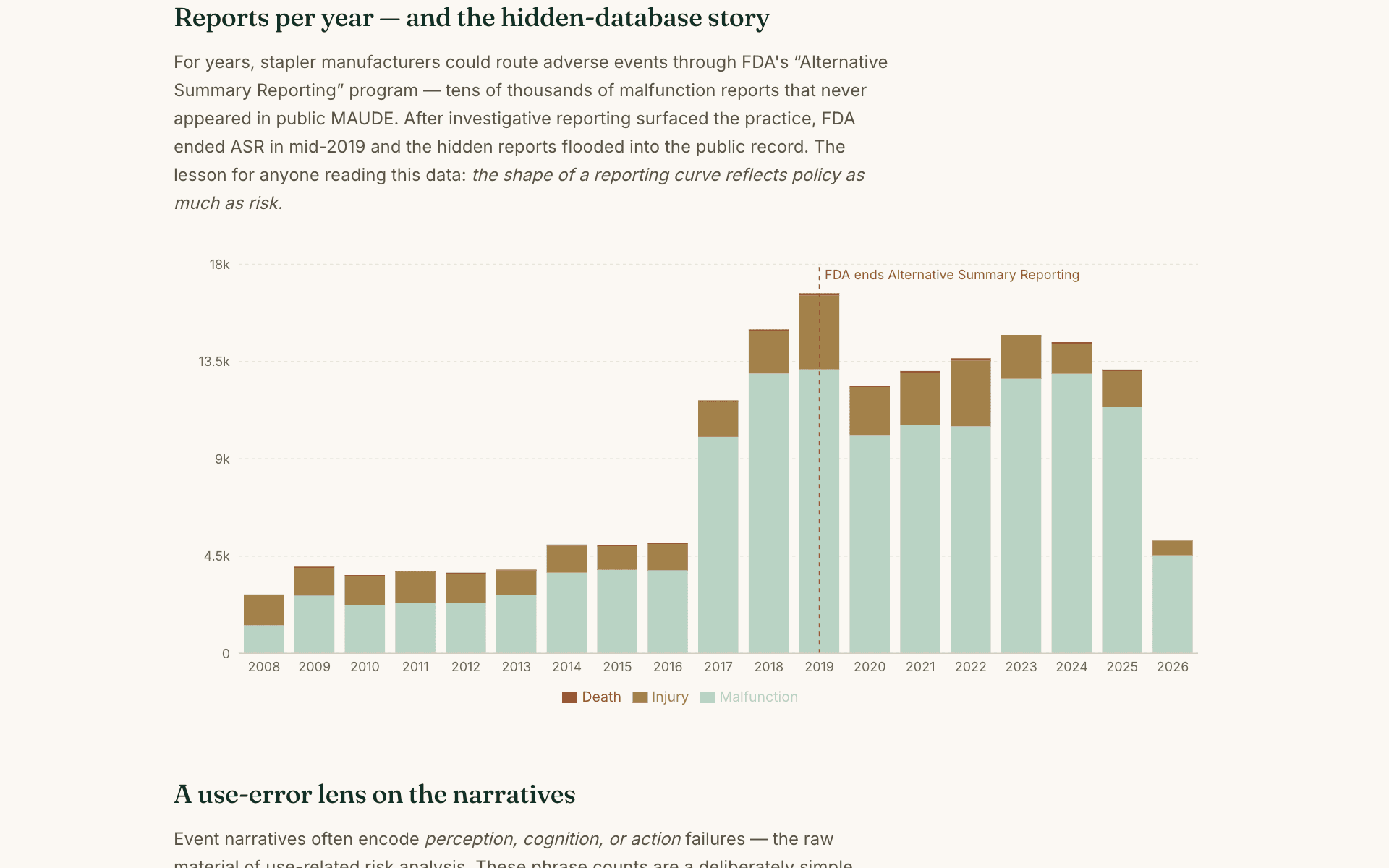
The 2019 ASR policy change, visible as data
Honesty as a design feature
The most deliberate design decision is the limitations section. MAUDE has no denominators, so counts can never become rates. Reporting is biased and incomplete. Narratives are usually secondhand, written by manufacturers. And a keyword match is a heuristic for finding reports worth reading—not a validated classifier, which would require trained reviewers and a reliability-checked coding scheme.
In regulated human factors work, knowing what your evidence cannot say is as load-bearing as knowing what it can. A tool that overstated its conclusions would be a worse portfolio piece than no tool at all.
What I learned
- Provenance before patterns—the biggest feature in this dataset is a policy change, not a device behavior. Context has to ship with the chart.
- Simple heuristics, honestly labeled, beat opaque scoring—a phrase count a reviewer can verify builds more trust than a black-box “risk score.”
- Post-market data is a hypothesis engine, not a verdict—its highest value to HFE teams is upstream, seeding formative work with documented field failures.
Methods & Stack
Analysis
- • Adverse-event trend analysis (event-type stratified)
- • Use-error phrase heuristics → PCA candidates
- • Narrative review workflow
- • Bias & limitations framing (no-denominator data)
Build
- • openFDA device/event API (live, revalidated daily)
- • Next.js App Router + TypeScript
- • Tailwind CSS + Recharts
- • Open source on GitHub